You can't review your way out of a god object
The post that started this was k10s’s “I’m going back to writing code by hand”. The author vibe-coded a GPU-aware Kubernetes dashboard for seven months — prompting Claude feature by feature and shipping what came back, with little architecture decided up front. That came to 234 commits over ~30 weekends, the model doing the typing. The velocity felt incredible; the GPU fleet view generated perfectly on the first try. Then one feature interaction broke live updates across multiple views, the author opened model.go, found 1690 lines, and was, in their word, horrified.
The wreckage was specific and structural. The Model struct had become a god object — UI widgets, the K8s client, per-view state, navigation history, caching, all in one place. Update() was a 500-line function with 110 switch/case branches. Resources had been flattened to []string with column identity carried by array index, so ra[3] meant “Alloc” until someone reordered a column and it silently meant something else.
None of that happened in a bad commit. It happened across two hundred good ones. The author’s own line is the whole thing: “the velocity makes you think you’re winning right up until everything collapses simultaneously.” The trend was visible the entire time. Nothing was watching it.
I built two tools in response to that failure mode. This post is half about why one of them is the wrong instrument for it, and half about what the right one actually did when I turned it on five of my own AI-built repos.
Disclosure, because it’s load-bearing. I wrote both. Anchor is a multi-role agent harness (Architect → Implementer → Reviewer → Memorial), and I’ve argued elsewhere that it earns its keep. arch-gate is the opposite kind of thing: a deterministic, zero-token gate. It grew out of Anchor and ships separately as sprag, but it is not Anchor — where the harness is a pipeline of models, the gate has no model in it at all. Two claims follow, “the harness can’t catch this” and “the gate did,” and both are worth nothing unless the reasoning is honest and the receipts are auditable. So I’ll mark where the harness genuinely wins, and every “after” in the second half was confirmed with the full test suite green.
The obvious response is a harness — and it can’t catch this
If a single agent rots a codebase over 234 commits, the natural fix is more agents: separate the one that writes from the one that judges. That’s the Generator–Evaluator pattern Anthropic’s harness-design paper is built on, it’s what Anchor’s four roles are, and it works. Anthropic’s own headline number is real: on an identical prompt, a 20-minute solo run cost $9 and produced broken work, while a 6-hour harnessed run cost $200 and produced something that functioned. I’ve watched Anchor’s cold-eye Reviewer catch CRITICAL bugs the Implementer had no reason to notice. The harness is not snake oil.
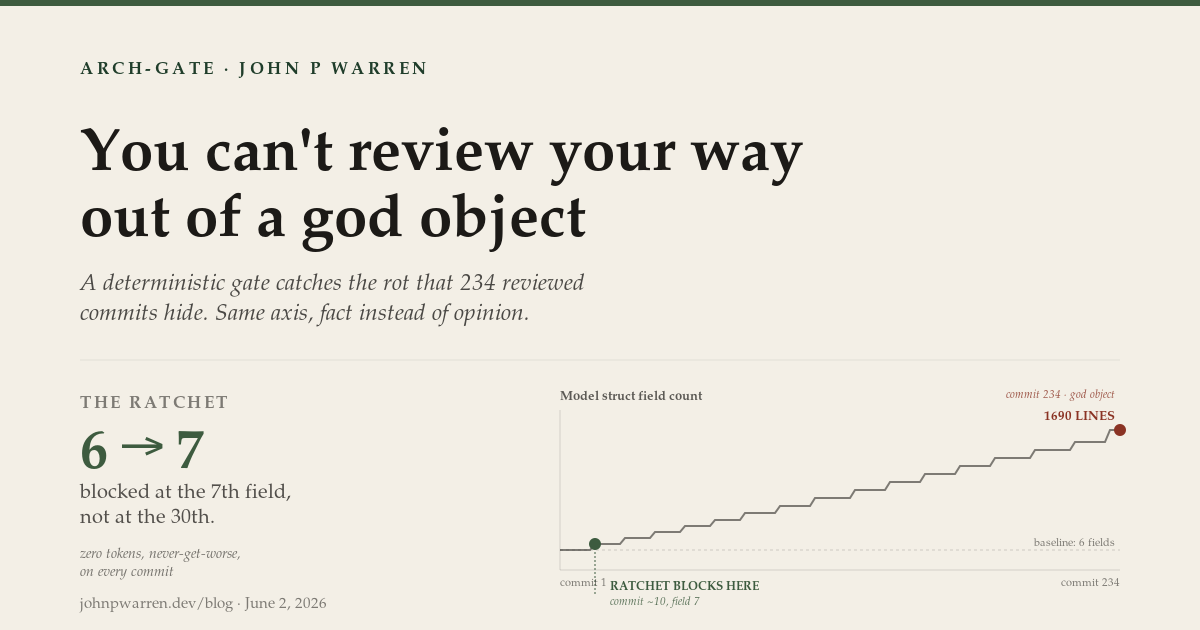
But it still ships god objects, and that’s the part no better harness fixes. Adversarial review and a green test suite answer one question: is this correct right now? A god object answers yes. The code works, the tests pass, the cold-eye Reviewer reads the diff and signs off, correctly, because on the axis it’s measuring there is no defect. Structural fragility is a different axis, invisible to both review and tests because nothing is wrong yet. The bill is deferred: the code ships looking great, works and works and works, until the day the structure can’t absorb the next change. That’s exactly how k10s broke: not on a failed test, but a feature interaction that took out live updates across views. By then the god object has tangled everything together, so the break is brutal to localize and brutal to fix.
And the review is blind to the trend by construction. Each of k10s’s 234 commits was a locally reasonable diff: one more field on Model, one more case in the switch, fine in isolation. A diff-scoped reviewer approves every one of them, because every one is fine on its own. The god object is the sum of 234 approved diffs, and no review of a single change can see an aggregate that only exists across the whole history. A harness’s architectural rules are promptware: “keep Model thin,” “no positional arrays.” Even a model that honors them perfectly per diff lets the accumulation through, because no single diff is the violation. A more expensive Claude, in a more disciplined pipeline, with a skeptical second Claude reviewing every change, still walks the same 234 reasonable commits into the same 1690-line file. Slower, and with a bigger bill.
A god object is a fact, not an opinion
Step back and look at what actually rotted in k10s. A struct grew past eight fields. A switch grew past some number of cases. Columns got addressed by magic integer index. Every one of those is a count. None of them is a judgment call. Facts don’t need an oracle — they need a measurement. And the moment a violation is a measurement rather than an opinion, you don’t want a probabilistic, expensive, occasionally-distracted model in the loop at all; you want a deterministic check that returns the same answer every time, costs nothing, and can’t be talked out of it.
That’s arch-gate. You author the architectural invariants yourself (the k10s author’s Tenet 1, write the architecture yourself), and the gate computes each metric over the real code (on a real AST, via ast-grep, for Go, TypeScript/JS, and Python) and blocks on a breach. No tokens, no session, no transcript. The invariants map straight onto the k10s failures:
| Invariant | What it counts | k10s failure it would have caught |
|---|---|---|
model-not-god-object | Model struct field count | the god object |
bounded-dispatch | switch m.view case count | the 110-branch Update() |
no-positional-rows | magic integer-index access (ra[3]) | positional fragility |
The load-bearing piece is the ratchet, and it’s the direct answer to “the velocity hid the trend.” The gate doesn’t only block an absolute maximum; it blocks any regression against a baseline computed from HEAD on every commit. Add one field to a six-field Model and the commit is blocked at 6→7 — not at 30, not at collapse. That’s how it sees what per-diff review can’t: it measures the accumulated state against a baseline, not the reasonableness of one change, so the trend that’s invisible across 234 individually-fine diffs becomes a single blocked commit the instant it crosses the line. The escape hatch stays visible — a // anchor:allow <id>: <reason> comment (the keyword is a tell: the gate grew out of Anchor) stops counting an instance as a violation but still reports it, so suppression is auditable, never silent.
Where the harness still wins
Here’s the line I have to draw carefully, because over-claiming here would be the same sin as the harness hype. The gate enforces the structural half of quality — size, coupling, dispatch growth, layering, positional fragility, test presence. It is completely blind to the behavioral half: is the logic correct? does this resampler preserve the covariance the calibration assumes? do the tests catch real bugs or just inflate a number? A struct field count will never tell you. Anchor’s cold-eye Reviewer once caught a σ² underflow that hit 60 of 66 statistical cells and never surfaced as a test failure, because the fixtures had inherited the same wrong assumption the code did — exactly the kind of thing only a separate, skeptical reader can catch, and no gate replaces it.
So the division of labor isn’t gate-versus-harness. Split it by what each side is good at: structural floor → the deterministic gate (counts and shapes, zero tokens, every commit, no oracle ceiling — the half k10s actually failed on); behavioral judgment → the model, used sparingly (correctness, hidden assumptions, test efficacy — where the expensive, probabilistic tokens are the only tool that works). The mistake isn’t running a harness. It’s using model tokens to enforce things that are deterministic facts — paying an oracle, per round, forever, to count struct fields it might miscount anyway.
What it did across five repos
That’s the argument. Here’s the evidence. I turned arch-gate on five of my own AI-built repos (none written with it in mind; it didn’t exist when most of the code shipped) and ran the adopt → remediate → freeze loop.

| Repo | God-files | God-functions | Tests after | Delivered |
|---|---|---|---|---|
| deploysignal | 18 → 0 | 31 → 0 | 980 pass / 0 fail | PR #31 |
| deploysignal-engine | 7 → 0 | 12 → 0 | 93 pass / 0 fail | PR #14 |
| runway | 7 → 0 | 12 → 0 | 523 pass / 0 fail | local (no remote) |
| tessera | 2 → 0 | 10 → 0 | 533 pass / 0 fail | PR #9 |
| anchor | 1 → 0 | 3 → 0 | 210 pass / 0 fail | pushed to main |
| Total | 35 → 0 | 68 → 0 | — | — |
Measure, for this remediation: god-file = source file >500 lines, god-function = function >80 lines, scoped to the source each gate watches (tests, generated bundles, and vendored copies excluded). Every “after” was validated by running the full suite to green; the pure-build scripts (deploysignal, tessera) were additionally checked by byte-identical golden output, not just syntax. (A whole-repo scan still surfaces a handful of god-files — runway’s five are all in tests/ — because the gate watches product source, not fixtures.)
The shape is consistent: the oldest, longest-running systems (deploysignal, runway) carried the most debt, accumulated exactly the way k10s described — slowly, across many individually-reasonable commits. But not every repo was bad; a few (clustersynth, anvil, cairn) scanned clean or nearly so. The honest headline isn’t “every AI codebase has seven god-files”; it’s “most accumulate some, and the ones that accumulate a lot do it invisibly.”
Complexity is the line now, not length
Driving god-files and god-functions to zero was the visible win, but it’s the cheap half — and length is a crude proxy, as I said above: a long-but-flat function is fine, a short and deeply-branched one is not. So I took my own advice. The gate’s primary signal is now McCabe cyclomatic complexity (>12); raw length stays only as a >150-line backstop. It’s ratcheted on the five repos in the table below (not the identical five as the cleanup table above — deploysignal-engine’s cleanup landed before the complexity ratchet rolled out, while cairn, which scanned nearly clean, is gated going forward):
| Repo | Gate watches | Complexity it freezes (blocks above) |
|---|---|---|
| deploysignal | engine, tools | 62 (engine 27 + tools 35) |
| anchor | . | 18 |
| tessera | . | 9 |
| runway | source dirs | ~8 |
| cairn | . | 1 |
Those numbers are deliberately not zero, and that’s the whole point of a complexity ratchet. It doesn’t exist to force every branchy function to zero — some are legitimately branchy and cohesive (a flat dispatcher, a classifier, a parser), and those are a visible // anchor:allow, not a silent pass. It exists to freeze the current count and refuse the next one. Length-to-zero is a one-time scrub; complexity-as-ratchet is the line that holds, because complexity is what actually tracks how hard the code is to follow and test. Every gated repo now blocks the next branchy function at the pre-commit hook, baseline from HEAD, no manual upkeep.
The receipts include the bugs
Naming what went wrong with my own tool is the trust move — most “tool validation” posts hide it. Running at portfolio breadth surfaced three fixes to arch-gate itself, all shipped mid-session:
- Walkers now skip Python
.venv/,site-packages/,__pycache__/. Without it, a root scan of runway falsely reported 1,848 god-files, almost all of them dependencies. - Scan now counts Go and Python god-functions. It was JS/TS-only, silently reporting 0 on Go and Python source — under-counting tessera and the Python parts of runway until the fix surfaced the rest.
- The scan respects
.gitignoreand counts tracked source only. Generated and ignored dirs (dist/,coordination/, build output) had been leaking into the totals; counting only tracked source is what makes the per-repo numbers trustworthy.
And it left things alone on purpose, which is where the rigor lives. Vendored files whose source-of-truth is another repo (a calibrator copied from deploysignal) were fixed upstream, not forked. Third-party clones (confseq, NAB) present for benchmarking were left untouched; reshaping them would diverge from upstream and defeat the point of having them. Each repo’s tests/ and generated bundles are fixtures and outputs, not architectural source. The gate scopes itself to the source under your control; that’s a discipline it enforces by not enforcing.
The remediation pattern itself was the same across all five: subagents did the mechanical file-splitting (a 1,421-line charts.py into a facade plus eight themed sub-modules), the pre-commit hook blocked any commit that made things worse, and the authoritative test suite between batches was ground truth, with facade re-exports preserving every public import path, so from runway.optimize import compute_runway still resolves and “no behavior change” means exactly that, not “no test failures, but every caller has to rewrite its imports.”
The gate doesn’t decay; the harness does
One durability note, because it’s the deepest reason to put the structural floor in a gate rather than a harness. Anthropic’s own discipline is that every harness component encodes an assumption about what the model can’t do — re-evaluate on each model release and delete the ones it no longer needs. Run that audit and the two tools come apart. A harness is made of model-weakness bets (a separate Architect role, a cold-eye Reviewer), and they expire as the base model improves; you keep paying full freight, O(tokens × rounds × model-price), for a quality lift that shrinks. The gate’s core was never a bet about the model: model-not-god-object is a statement about what your architecture should be, and a stronger model writes the thirteenth Model field faster without making the thirteenth field acceptable. It costs ~0 per commit and the load-bearing part of it is exactly what the audit can’t retire. The thing watching your architecture should be the one input to the system that doesn’t get more expensive and less necessary over time.
Close
The k10s author went back to writing code by hand and reached the same conclusion I did from the other direction: write the architecture yourself, before you prompt. Where I’d push it further is on what happens after you write it down. Their architecture lived in their head and in CLAUDE.md — somewhere a model has to choose to honor, every commit, forever. That’s the gap two hundred good commits fell through. You don’t have to choose between vibe-coding and hand-writing every line; you have to stop trusting a model — yours, or a more expensive pipeline of them — to be the only thing standing between you and a god object. Write the invariant down once, in a form that can’t be reviewed-away or drifted-past, and let a gate that costs nothing refuse the thirteenth field on every commit. I ran that across five repos this week; the line is holding.
The transferable principle: before you adopt a tool to enforce something, check whether it’s a fact or an opinion. Facts go to a deterministic gate. Opinions go to the model. The cost-and-correctness curves point opposite directions, and they don’t cross.
Reserve the tokens for the problems that are actually opinions.